Keyword Search Modules¶
DAS Keyword Search modules
Module author: Vidmantas Zemleris <vidmantas.zemleris@gmail.com>
Overview¶
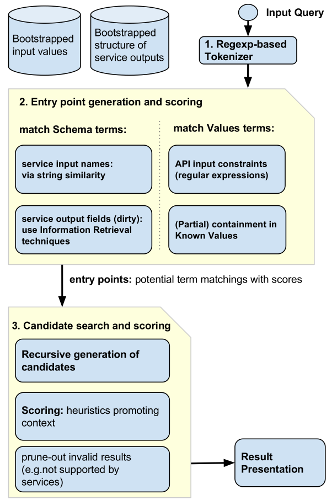
The basic keyword search workflow:
- The query is tokenized (including shallow parsing for key=val patterns and quotes)
- Then by a number of entity matchers the entry points are generated (matches of each keyword or the few nearby keywords into some of the schema or value terms which make part of a structured query)
- Exploring the various combinations of the entry points the candidates for query suggestions are evaluated and ranked
- The top results are presented to the users (generating a valid DAS query and a providing a readable query description)

Adapters to access Metadata¶
Contain meta-data related functions:
- accessing integration schema: fields, values, constraints on inputs/queries
- tracking fields available
- tracking known (input field) values
The schema adapter¶
Provide a layer of abstraction between Keyword Search and the Data Integration System.
-
DAS.keywordsearch.metadata.schema_adapter2.ApiDef¶ alias of
ApiInputParamsEntry
-
class
DAS.keywordsearch.metadata.schema_adapter2.DasSchemaAdapter¶ provides an adapter between keyword search and Data integration system.
-
classmethod
are_wildcards_allowed(entity, wildcards, params)¶ Whether wildcards are allowed for given inputs
currently only these simple rules allowed: site=W* dataset=W* dataset site=T1_CH_* dataset site=T1_CH_* dataset=/A/B/C file dataset=/DoubleMu/Run2012A-Zmmg-13Jul2012-v1/RAW-RECO site=T1_* file block=/A/B/C#D file file=W* dataset=FULL file file=W* block=FULL
# these are supported (probably) because of DAS-wrappers file dataset=*DoubleMuParked25ns* file dataset=*DoubleMuParked25ns* site=T2_RU_JINR
-
check_result_field_match(fieldname)¶ checks for complete match to a result field
-
entities_for_inputs(params)¶ lists entities that could be retrieved with given input params
-
get_api_param_definitions()¶ returns a list of API input requirements
-
get_result_field_title(result_entity, field, technical=False, html=True)¶ returns name (and optionally title) of output field
-
init(dascore=None)¶ initialization or re-initialization
-
list_result_fields(entity=None, inputs=None)¶ lists attributes available in all service outputs (aggregated)
-
validate_input_params(params, entity=None, final_step=False, wildcards=None)¶ checks if DIS can answer query with given params.
-
validate_input_params_lookupbased(params, entity=None, final_step=False, wildcards=None)¶ checks if DIS can answer query with given params.
-
classmethod
Gathers the list of fields available in service outputs
-
DAS.keywordsearch.metadata.das_output_fields_adapter.flatten(list_of_lists)¶ Flatten one level of nesting
-
DAS.keywordsearch.metadata.das_output_fields_adapter.get_outputs_field_list(dascore)¶ makes a list of output fields available in each DAS entity this is taken from keylearning collection.
-
DAS.keywordsearch.metadata.das_output_fields_adapter.get_titles_by_field(dascore)¶ returns a dict of titles taken from presentation cache
-
DAS.keywordsearch.metadata.das_output_fields_adapter.is_reserved_field(field, result_type)¶ returns whether the field is reserved, e.g. *.error, *.reason, qhash
-
DAS.keywordsearch.metadata.das_output_fields_adapter.print_debug(dascore, fields_by_entity, results_by_entity)¶ verbose output for get_outputs_field_list
-
DAS.keywordsearch.metadata.das_output_fields_adapter.result_contained_errors(rec)¶ decide whether keylearning record contain errors (i.e. as responses from services contained errors) and whether the record shall be excluded
DAS Query Language definitions¶
defines DASQL and keyword search features, e.g. what shall be considered as: * word * simple operators * aggregation operators (not implemented)
-
DAS.keywordsearch.metadata.das_ql.flatten(list_of_lists)¶ Flatten one level of nesting
-
DAS.keywordsearch.metadata.das_ql.get_operator_synonyms()¶ return synonyms for das aggregation operators (not used yet)
Tokenizing and parsing the query¶
- Module description:
first clean up input keyword query (rm extra spaces, standardize notation)
- then it tokenizes the query into:
- individual query terms
- compound query terms in brackets (e.g. “number of events”)
- phrases: “terms operator value” (e.g. nevent > 1, “number of events”=100)
-
DAS.keywordsearch.tokenizer.cleanup_query(query)¶ Returns cleaned query by applying a number of transformation patterns that removes spaces and simplifies the conditions
>>> cleanup_query('number of events = 33') 'number of events=33'
>>> cleanup_query('number of events > 33') 'number of events>33'
>>> cleanup_query('more than 33 events') '>33 events'
>>> cleanup_query('X more than 33 events') 'X>33 events'
>>> cleanup_query('find datasets where X more than 33 events') 'datasets where X>33 events'
>>> cleanup_query('=2012-02-01') '= 20120201'
>>> cleanup_query('>= 2012-02-01') '>= 20120201'
-
DAS.keywordsearch.tokenizer.get_keyword_without_operator(keyword)¶ splits keyword on operator
>>> get_keyword_without_operator('number of events >= 10') 'number of events'
>>> get_keyword_without_operator('dataset') 'dataset'
>>> get_keyword_without_operator('dataset=Zmm') 'dataset'
-
DAS.keywordsearch.tokenizer.get_operator_and_param(keyword)¶ splits keyword on operator
>>> get_operator_and_param('number of events >= 10') {'type': 'filter', 'param': '10', 'op': '>='}
>>> get_operator_and_param('dataset')
>>> get_operator_and_param('dataset=Zmm') {'type': 'filter', 'param': 'Zmm', 'op': '='}
-
DAS.keywordsearch.tokenizer.test_operator_containment(keyword)¶ returns whether a keyword token contains an operator (this is useful then processing a list of tokens, as only the last token may have an operator)
>>> test_operator_containment('number of events >= 10') True
>>> test_operator_containment('number') False
-
DAS.keywordsearch.tokenizer.tokenize(query)¶ tokenizes the query retaining the phrases in brackets together it also tries to group “word operator word” sequences together, such as
"number of events">10 or dataset=/Zmm/*/raw-reco
so it could be used for further processing.
special characters currently allowed in data values include: _*/-
For example:
>>> tokenize('file dataset=/Zmm*/*/raw-reco lumi=20853 nevents>10' '"number of events">10 /Zmm*/*/raw-reco') ['file', 'dataset=/Zmm*/*/raw-reco', 'lumi=20853', 'nevents>10', 'number of events>10', '/Zmm*/*/raw-reco'] >>> tokenize('file dataset=/Zmm*/*/raw-reco lumi=20853 dataset.nevents>10' '"number of events">10 /Zmm*/*/raw-reco') ['file', 'dataset=/Zmm*/*/raw-reco', 'lumi=20853', 'dataset.nevents>10', 'number of events>10', '/Zmm*/*/raw-reco'] >>> tokenize("file dataset=/Zmm*/*/raw-reco lumi=20853 dataset.nevents>10" "'number of events'>10 /Zmm*/*/raw-reco") ['file', 'dataset=/Zmm*/*/raw-reco', 'lumi=20853', 'dataset.nevents>10', 'number of events>10', '/Zmm*/*/raw-reco'] >>> tokenize('user=vidmasze@cern.ch') ['user=vidmasze@cern.ch']
Entity matchers¶
Contain entity matching related functions:
- Name matching / custom String distance
- Chunk matching (multi-word terms into names of service output fields)
- Value matching
- And CMS specific dataset matching
Value matching¶
module provide custom Levenshtein distance function
-
DAS.keywordsearch.entity_matchers.string_dist_levenstein.levenshtein(string1, string2, subcost=3, modification_middle_cost=2)¶ string-edit distance returning min cost of edits needed
-
DAS.keywordsearch.entity_matchers.string_dist_levenstein.levenshtein_normalized(string1, string2, subcost=2, maxcost=3)¶ return a levenshtein distance normalized between [0-1]
Name matching: multi-term chunks representing field names¶
Modules for matching chunks of keywords into attributes of service outputs. This is obtained by using information retrieval techniques.
Generating and Ranking the Query suggestion¶
A ranker implemented in Cython and built into a C extension¶
A ranker combine scores of individual keywords to make up the final score. It evaluates the possible combinations and provides a ranked list of results (i.e. query suggestions).
the source code is in DAS.keywordsearch.rankers.fast_recursive_ranker which is compiled into DAS.extensions.fast_recursive_ranker (with help of DAS/keywordsearch/rankers/build_cython.py )
Presenting the Results to the user¶
Presentation of query suggestions
The module contain functions for presenting the results as DASQL and formatting/coloring them in HTML.
-
DAS.keywordsearch.presentation.result_presentation.dasql_to_nl(dasql_tuple)¶ - Returns natural language representation of a generated DAS query
- so to explain users what does it mean.
-
DAS.keywordsearch.presentation.result_presentation.fescape(value)¶ escape a value to be included in html
-
DAS.keywordsearch.presentation.result_presentation.result_to_dasql(result, frmt='text', shorten_html=True, max_value_len=26)¶ returns proposed query as DASQL in there formats:
text, standard DASQL
- html, colorified DASQL with long values shortened down (if shorten_html
is specified)
-
DAS.keywordsearch.presentation.result_presentation.shorten_value(value, max_value_len)¶ provide a shorter version of a very long value for displaying in (html) results. Examples include long dataset or block names.